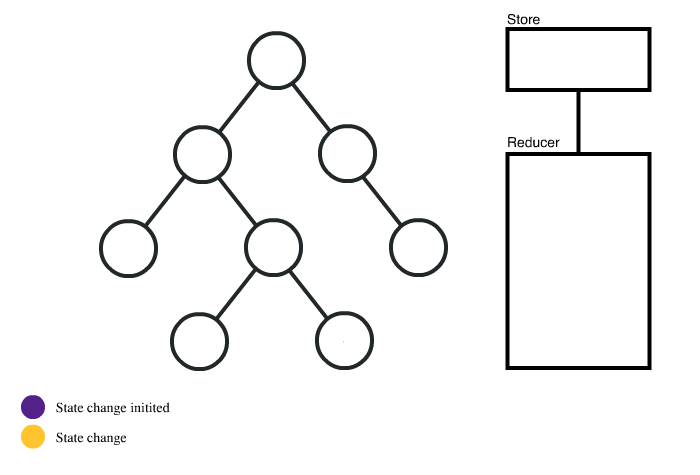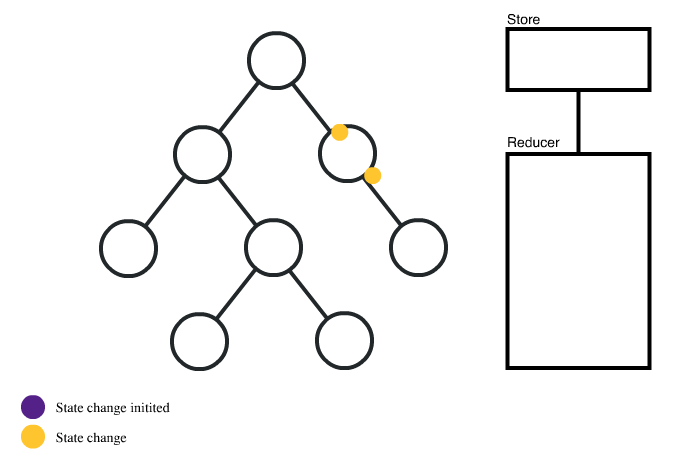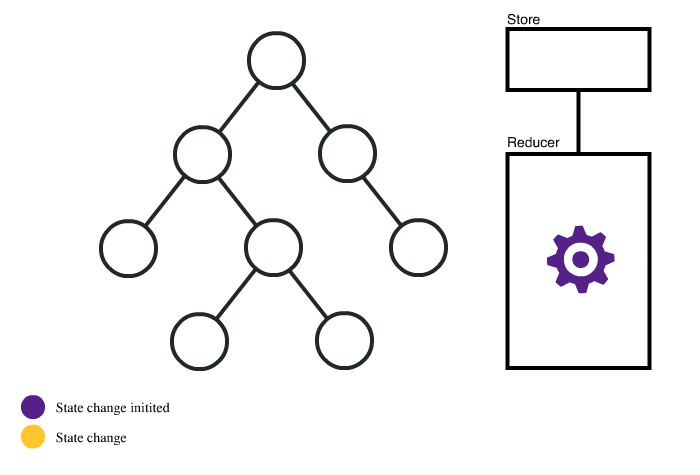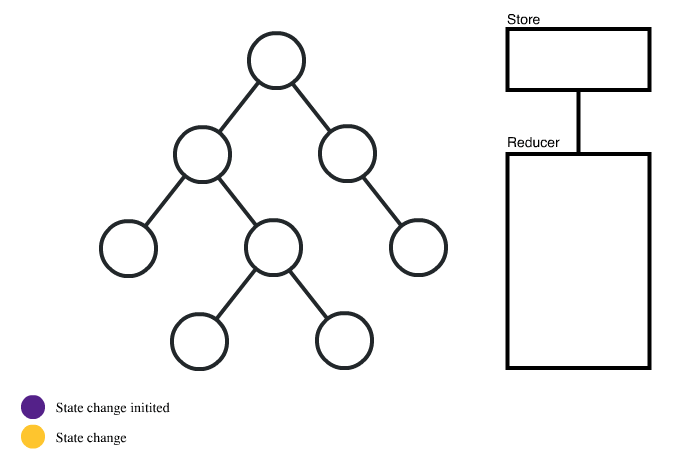
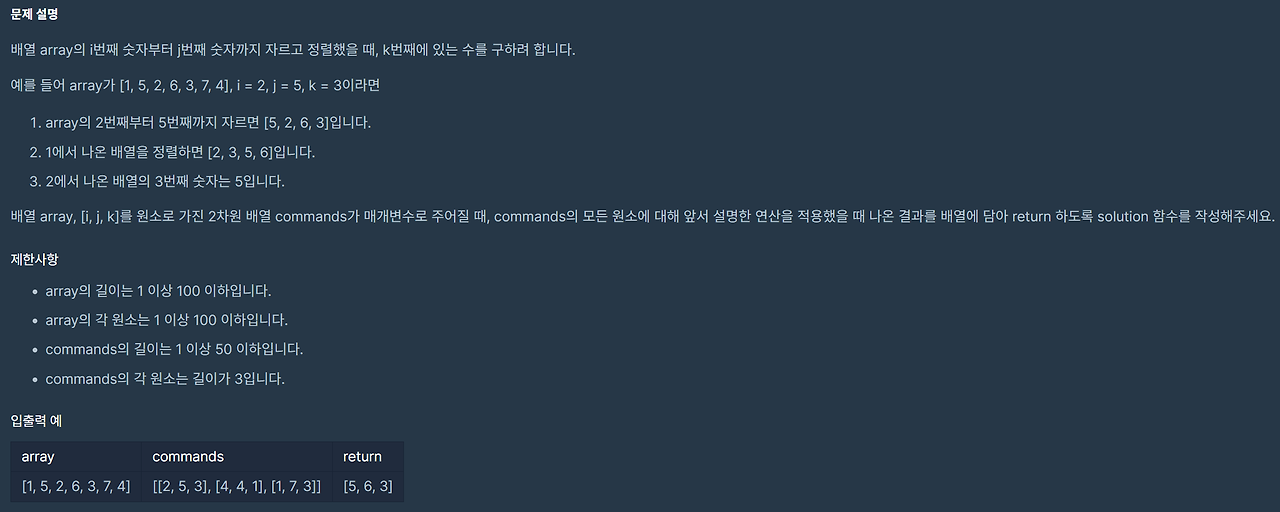
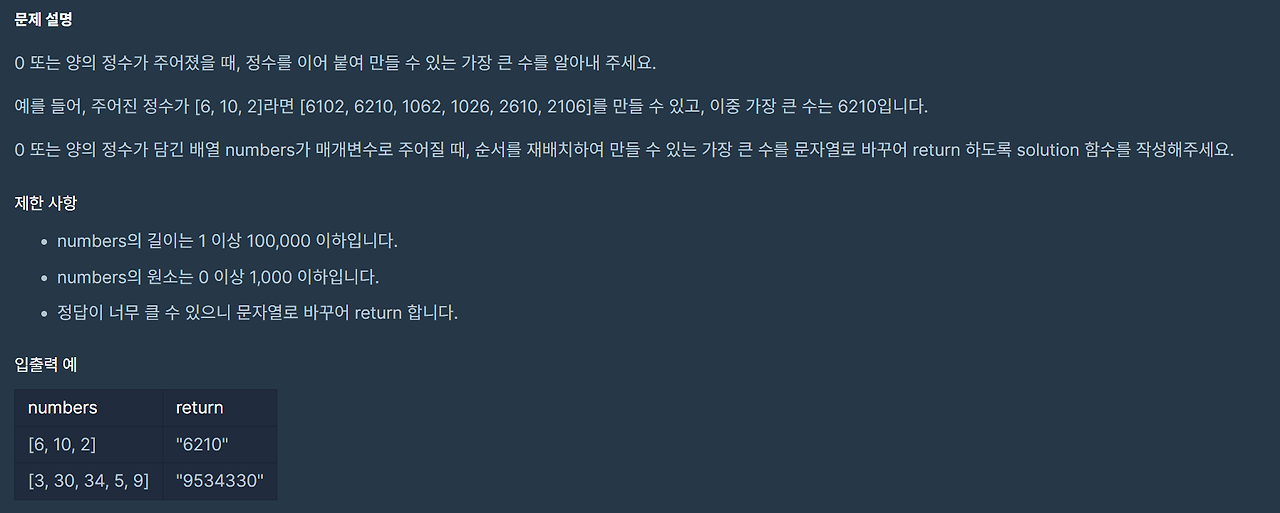
- 웹 개발에서 WAS는 클라이언트의 요청을 처리하고 동적인 웹 콘텐츠를 생성하는 핵심 컴포넌트이다.
- 프론트엔드와 백엔드 간의 원활한 통신을 가능하게 하며, 웹 애플리케이션의 성능, 보안, 확장성을 좌우하는 중요한 요소이다.
WAS
- 웹 애플리케이션을 실행하고 관리하는 서버 소프트웨어
- 클라이언트로부터 HTTP 요청을 받아 처리하고, 동적인 웹 페이지나 데이터를 생성하여 응답을 반환한다.
- WAS는 주로 백엔드 로직을 처리하며, 데이터베이스와의 상호작용, 인증 및 권한 관리, 비즈니스 로직 실행 등을 담당한다.
WAS와 Web Server의 차이
- 웹 서버 : 주로 정적인 콘텐츠들을 제공하며, HTTP 요청을 처리한다.
- 대표적으로 Apache, Nginx 등이 존재한다.
- 웹 애플리케이션 서버 : 동적인 콘텐츠를 생성하고, 복잡한 비즈니스 로직을 처리한다.
- 대표적으로 Tomcat, Jetty, WildFly 등이 있다.
⇒ WAS는 웹 서버와 함께 사용되는 경우가 많으며 웹 서버가 정적인 콘텐츠를 제공하고 WAS가 동적인 처리를 담당하여 효율적인 자원 관리를 가능하게 한다.
WAS의 주요 역할
- 동적 콘텐츠 역할
- 사용자 요청에 따라 동적으로 웹 페이지나 데이터를 생성하여 응답한다.
- 비즈니스 로직 처리
- 애플리케이션의 핵심 기능을 구현하는 로직을 실행한다.
- 데이터베이스 연동
- 데이터베이스와의 상호 작용을 관리하여 데이터를 조회, 삽입, 수정, 삭제한다.
- 인증 및 권한 관리
- 사용자 인증 및 권한 부여를 통해 보안을 유지
- 세션 관리
- 사용자 세션을 관리하여 상태 정보를 유지
- 트랜잭션 관리
- 데이터의 일관성을 유지하기 위해 트랜잭션 관리
WAS의 주요 기능
- 로드 밸런싱
- 여러 대의 서버에 요청을 분산시켜 서버 부하를 줄이고, 가용성을 높임
- 클러스터링
- 여러 대의 WAS 인스턴스를 클러스터로 구성하여 고가용성과 확장성을 제공
- 캐싱
- 자주 요청되는 데이터를 캐시에 저장하여 응답 속도 향상
- 보안
- SSL/TLS 지원, 인증 및 권한 관리, 데이터 암호화 등을 통해 보안을 강화
- 모니터링 및 로깅
- 애플리케이션의 성능을 모니터링하고, 로그를 기록하여 문제를 진단하고 해결
- API 관리
- RESTful API나 GraphQL API를 제공하여 프론트엔드와의 원활한 통신을 지원
프론트엔드와 WAS의 연동
- 프론트엔드 애플리케이션은 WAS와 API를 통해 데이터를 주고받으며, 사용자 인터페이스를 동적으로 업데이트한다.
- API 설계
- RESTful API 또는 GraphQL을 설계하여 프론트엔드와 백엔드 간의 통신 규약을 정의합니다.
- HTTP 요청 처리
- 프론트엔드에서 fetch 또는 axios 같은 라이브러리를 사용하여 WAS의 엔드포인트에 HTTP 요청을 보냅니다.
- 데이터 포맷
- 일반적으로 JSON 형식을 사용하여 데이터를 주고 받습니다.
- 인증 및 권한
- JWT나 OAuth를 사용하여 인증 및 권한을 관리합니다
- 에러 핸들링
- 프론트엔드에서 백엔드로부터의 에러 응답을 적절히 처리하여 사용자에게 알립니다.
- CORS 설정
- WAS에서 CORS를 설정하여 프론트엔드와의 교차 요청을 허용합니다.
결론
- WAS는 현대 웹 애플리케이션의 핵심 구성 요소로 프론트엔드와 백엔드 간의 원활한 통신을 지원하고, 애플리케이션의 성능과 보안을 책임집니다. 다양한 WAS가 존재하며, 프로젝트의 요구사항에 맞는 적절한 WAS를 선택하는 것이 중요합니다.
- WAS의 존재에 대해 잘 몰랐기 때문에 그 동안 서버라고 말하면 모두 웹 서버를 말하는 줄 알았는데 오히려 프론트와의 긴밀한 연결은 WAS와 이어지고 있다는 것을 깨달았습니다. 두 서버가 왜 다른 지 이해했고, WAS를 어떤 시각으로 바라보고 프론트에서 적절하게 사용해야 하는 지 알았습니다.
'TIL' 카테고리의 다른 글
| AMP (Accelerated Mobile PAges) (0) | 2024.08.26 |
|---|---|
| React (Redux , Context API, 클래스형과 함수형) (0) | 2024.08.22 |
| 자바스크립트의 ES6 (0) | 2024.08.21 |
| 자바스크립트의 this (0) | 2024.08.20 |
| 자바스크립트의 타입 (0) | 2024.08.19 |